
Keine Datenbank braucht Indexe – nur die Applikationen
This post might contain affiliate links. We may earn a commission if you click and make a purchase. Your support is appreciated!
ich weiß, der Spruch ist geklaut aber er passt einfach so gut…
Man kann von Indexen halten was man will, aber man kommt halt nicht um sie herum.
Markus Winand schreibt in seinem Blog eine einfache aber geniale Einleitung zum Thema Indexe:
„Ein Index macht die Abfrage schnell“ ist die einfachste Beschreibung, die ich jemals für einen Datenbank-Index gehört habe. Obwohl sie seine wichtigste Eigenschaft gut erfasst, …
Wenn man sich eine einfache Tabelle ansieht, dann enthält diese von Haus aus keine Indexe.
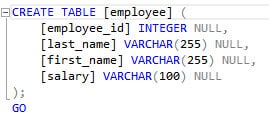
Der Ausführungsplan für ein einfaches SELECT sieht dann so aus:

Wie man erkennen kann, wird ein Full Table Scan durchgeführt. Das funktioniert zwar technisch und mag bei einfachen Abfragen oder kleinen Tabellen auch besser sein, aber für größere Tabellen und komplexere Abfragen fehlt hier mindestens ein Index. Also fügen wir der Tabelle zumindest einen Index hinzu, in diesem Fall einen Primary Key.
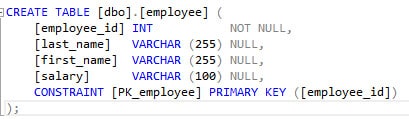
Daraus wird dann der folgende Ausführungsplan und man erkennt direkt den Unterschied zu vorher. Die „Kosten“ fallen zwar immer noch zu 100% auf den Index, aber auch nur weil dieser Testfall zu einfach ist.

Am besten kann sich das obige Bespiel mit dem alten Telefonbuch verdeutlichen:
Früher (bevor es intelligente Telefone/Handys gab) hatte jeder einen Notizbuch, in dem er die wichtigsten Daten seines Freundeskreis oder seiner Bekannten notierte.
Manfred Müller Bürgermeister-Glück-Straße 25 1245 Beispielhausen 3 10.08.1955 04158 / 523 487 956
Mit der Zeit füllte sich dieses Notizbuch, die Einträge völlig unsortiert, man schrieb einfach hinter einander weg. Irgendwann (nach mehrfachen Suchen) wusste man selber wer wo auf welcher Seite steht und fand so schneller zum Beispiel eine Telefonnummer.
Um beim obigen Beispiel zu bleiben, bei einem Full Tablescan müssen erst alle Seiten einer Tabelle gelesen werden, bis ein Ergebnis geliefert werden kann. Verfügt die Tabelle allerdings über einen Index, so werden die zu lesenden Seiten anhand des Indexes ermittelt und die Abfrage liefert schneller ein Ergebnis zurück, da nun nicht mehr alle Seiten (Pages) gelesen werden müssen.
Nun steigt mit der Zeit die Anzahl der Einträgen und das Führen eine unsortieren Notizbuches wurde immer unübersichtlicher, so dass man sich dann ein optimiertes Notizbuch mit Index (Inhaltsverzeichnis) kaufte… aaahhh ein Index.
Hier konnte man seinen Bekanntenkreis nach Anfangsbuchstaben sortieren, zum Beispiel mit dem ersten Buchstaben des Nachnamens oder auch des Vornamens (je nach Vorlieben oder was man sich besser merken konnte 😉 )
Genauso funktioniert unsere Tabelle im SQL-Server oben auch, ohne (hier Clustered) Index waren es einfach nur unsortierte Einträge, nach dem wir den Primary Key (einen Index) auf die Tabelle gelegt haben, hatten wir sozusagen ein Inhaltsverzeichnis erstellt und das Suchen im Adressbuch ging wesentlich einfacher und schneller. Ebenso verhält sich ein SQL Server mit seinen Indexen, ein Index ist sozusagen eine Extra-Seite, welche die Namen und einen Verweis auf die Seite beinhaltet, so dass nur noch einzelne Seiten beim Suchen nach dem Namen durchsucht werden müssen.
Denn in einer Tabelle werden die Einträge hintereinander weg speichert, es gibt keine Sortierung. Heißt mit einem FullTable stellt der SQL Server sicher, dass auch tatsächlich alle relevanten Einträge gefunden werden, dazu muss er erst alle Seiten lesen und durchsuchen. Bei einem Index Scan wird nur das Inhaltsverzeichnis durchsucht und die dort vermerkten Seiten werden gelesen, was wesentlich schneller geht als ein FullTable Scan.
Hierzu sehen wir uns erstmal die zwei Haupt-Index-Typen an, welche Typen gibt es bzw welche Index-Typen werden am häufigsten verwendet:
- Clustered Indexes
- Tabellen ohne Clustered Index werden als HEAP bezeichnet
- Zeilen werden in einer logischen Reihenfolge gespeichert
- nur ein Clustered-Index pro Tabelle
- alle Daten werden in den Leafs gespeichert
- Non-Clustered Indexes
- Tabelle als Heap oder Clustered Index strukturiert
Heap = Index ID 0
Clustered-Index = Index ID 1 - Weitere Indizes können erstellt werden, diese werden als Non clustered Indexes (Index ID 2+) bezeichnet
- Indexe sind einzelne Objekte in der Tabelle
- Auf Leaf Ebene ist nur einen Zeiger vorhanden, der die Information enthält auf wo der Rest der Spalten zu finden ist.
- Tabelle als Heap oder Clustered Index strukturiert
Christian Bolton | Technical Director, Coeo
Graeme Malcolm | Microsoft
Notizbuch und Tabelle haben eine weitere Gemeinsamkeit… es kommen Einträge hinzu, Einträge werden gelöscht oder verändert, also die typischen Insert, Delete oder Update Statements.
Was passiert in solchen Fällen aber mit dem Index?
Der muss doch eigentlich auch angepasst werden?
Ich versuche mal einen Einstieg in dieses Thema anhand des Clustered Indexes:
- Insert
Bei einem Insert-Statement muss jede neue Zeile an ihrer logisch richtigen Position untergebracht werden, dabei kann es zu einem Page-Split der Tabelle kommen (da andere Zeilen „verschoben“ werden müssen). - Update
Wenn am ClusterKey (also der Spalte des Keys) der veränderten Spalte nichts geändert wird, also die Zeile an der selben Position bleibt, bleibt auch die Position innerhalb der Page identisch.
Wenn sich die Größe der Zeile durch das Update ändert und die Zeile nicht mehr ganz in die Page passt, kommt es zu einem Page-Split der Tabelle.
Wenn doch der Wert des ClusterKey verändert wird, so muss die Zeile entfernt werden und an einer neuen Position in einer anderen Page wieder gespeichert werden. Dadurch kommt es zu Leerräumen innerhalb der Pages. - Delete
Ähnlich wie das Neu-Positionieren von Zeilen entstehen auch durch Delete-Statements Leerraum in den jeweiligen Pages.
Nun werden in Datenbanken und den Tabellen täglich eine Vielzahl von Daten neu geschrieben, Daten verändert oder gelöscht, so dass innerhalb der Indexe auch eine gewisse Unordnung entsteht. Diese „Unordnung“ – fachlich auch als Fragmentation bezeichnet – sorgt mit zunehmender Zeit (Häufigkeit der Veränderungen und Datenwachstum) für eine nicht optimale Verteilung der Daten innerhalb der Pages, was zu einer Reduzierung der Abfrage-Performance führt und im schlimmsten Fall die Performance der ganze Applikation beeinträchtigen kann.
Daher empfehle eine regelmäßige Pflege aller Indexe!
Dazu mehr in einem weiteren SQL Server Blogpost zum Thema Indexpflege…
Indexe sind außerordentlich wichtig für Applikationen, damit komplexe Abfragen oder auch einfache Queries auf große Datenmengen einen verbesserten Ausführungsplan zeigen.
This post might contain affiliate links. We may earn a commission if you click and make a purchase. Your support is appreciated!
Björn arbeitet auch weiterhin aus Mexiko als Senior Consultant – Microsoft Data Platform und Cloud für die Kramer&Crew in Köln. Auch der Community bleibt er aus der neuen Heimat treu, er engagiert sich auf Data Saturdays oder in unterschiedlichen Foren. Er interessiert sich neben den Themen rund um den SQL Server, Powershell und Azure SQL für Science-Fiction, Backen 😉 und Radfahren.
Amazon.com Empfehlungen
Damit ich auch meine Kosten für den Blog ein wenig senken kann, verwende ich auf diese Seite das Amazon.com Affiliate Programm, so bekomme ich - falls ihr ein Produkt über meinen Link kauft, eine kleine Provision (ohne zusätzliche Kosten für euch!).
Auto Amazon Links: Keine Produkte gefunden.

